Test Cases
Testcases: Evaluate and Improve Your AI Prompts with Precision
Getting an AI response is easy.
Knowing whether that response is accurate, reliable, and consistent is the real challenge.
GTWY solves this with Testcases — your built-in system for measuring, scoring, and improving AI prompts with scientific precision.
It turns guesswork into data.
What Are Testcases in GTWY?
Testcases allow you to test how well your system prompt and configuration perform against a specific expected response.
Whether you’re building an assistant, chatbot, or decision-making workflow, testcases help you measure how closely the AI’s output matches what you intended.
You can even create testcases directly from your bridge history, using previous conversations as examples to test consistency and reliability.
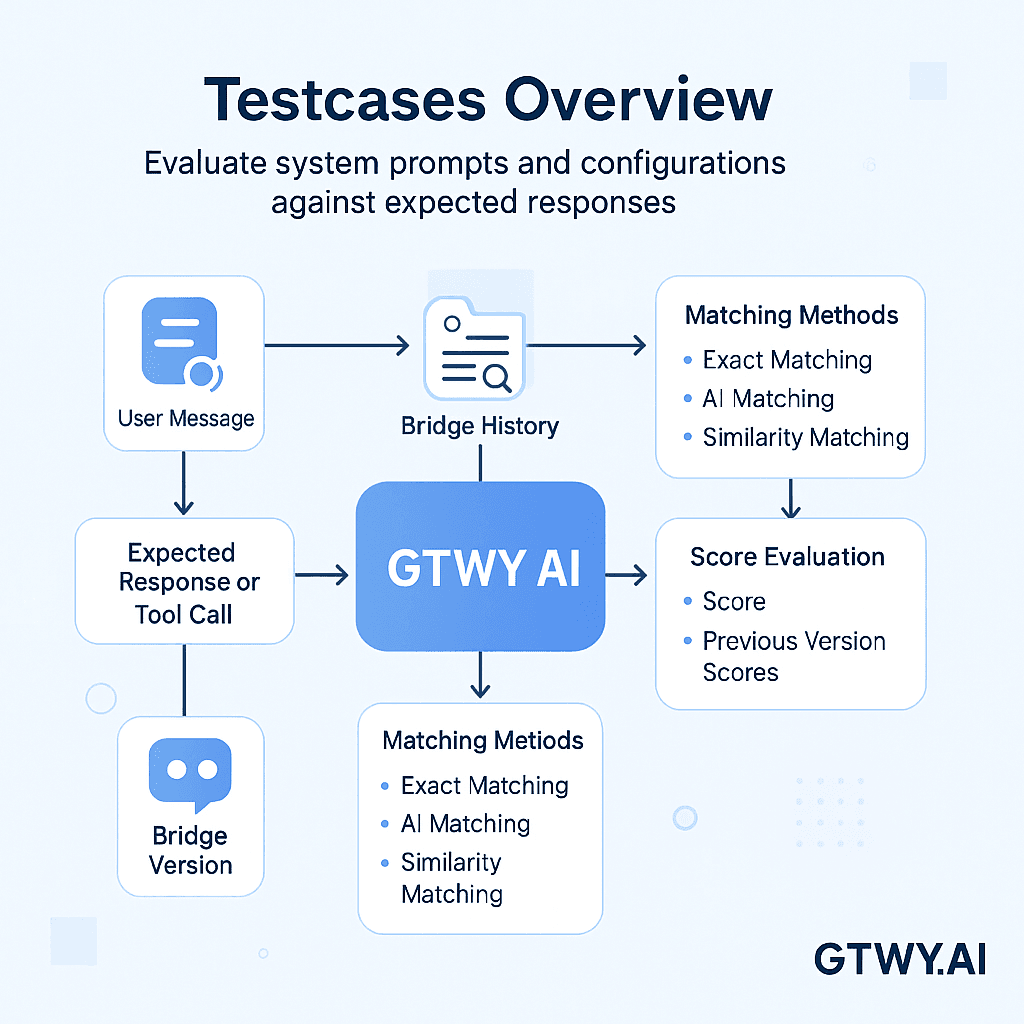
How It Works ?
Every testcase in GTWY includes a few simple inputs:
User Message: The prompt or question you want the AI to respond to.
Expected Response or Tool Call: The ideal or target output you want from your agent. (Note: tools are not actually called during testcase runs.)
Bridge Version: The version of your bridge or agent configuration to be tested.
Once you’ve set this up, GTWY runs the test by calling the selected LLM API (such as OpenAI or Anthropic) with your chosen version’s settings — and then evaluates the output using smart comparison methods.
Matching Methods
GTWY supports three evaluation methods, depending on how strictly or intelligently you want your tests to be scored:
1. Exact Matching
This method checks for an exact match — both the value and structure of the response must be identical to the expected one.
Use it for objective, rule-based tasks like code generation, data extraction, or factual queries.
2. AI Matching
Here, GTWY uses another language model to evaluate accuracy and meaning.
Instead of checking for word-by-word matches, it assesses how semantically close the AI’s answer is to the expected response and assigns a score.
Perfect for tasks like summarization, paraphrasing, or open-ended writing.
3. Similarity Matching
This method measures the cosine similarity between the expected and actual responses — essentially checking how similar they are in meaning or tone.
It gives you a numerical score that represents how close the responses are on a scale from 0 to 1.
Scoring and Evaluation
GTWY provides detailed scoring insights so you can track and improve your agent’s performance over time.
Each testcase generates a score (instead of a simple pass/fail result), showing how well the actual response aligns with the expected one.
You can:
Compare current results with previous version scores.
Identify where your agent is improving — or where fine-tuning is needed.
Make iterative updates to your prompts and test again.
This continuous feedback loop helps you refine your AI agents with data-driven precision.
Why Testcases Matter
Building AI agents is not just about creativity — it’s about consistency and reliability.
With Testcases, you can:
Validate your AI’s accuracy before going live.
Benchmark new versions of your agents.
Detect regressions early during updates.
Measure progress with clear, comparable metrics.
Whether you’re working on customer support agents, content generators, or research tools — testcases help ensure your AI behaves exactly as intended.
Final Thoughts
Testcases in GTWY turn AI evaluation into a systematic, data-driven process.
Instead of guessing whether a prompt works, you measure it, score it, and improve it.
If you update your agent or tweak a prompt, don’t hope it works — prove it with Testcases.